Overview
The SQL Transform allows you to write a custom SQL statement to transform data.
EdgeCore will automatically detect the usage of any other Pipeline Node table, and therefore modify the Pipeline topology to depict the new relationships.
It is strongly recommended that you use the SQL Transform when performing complex transforms or filters instead of manipulating data outside the Edge product so that your tacit knowledge of how the data is being manipulated is saved in your backups.
Create a SQL Transform
- Mouse over the right side of the node and click the gear icon for the node.
- Click the “New” icon
- Select the “New Transform” option.
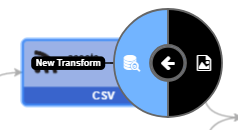
The “Choose a Transform” dialog will appear, showing the available transforms in the system. Select the “SQL Transform” option. This will launch the SQL Transform Wizard.
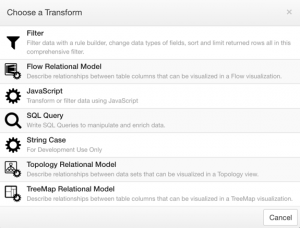
SQL Transform Wizard
The SQL Transform Wizard has five steps.
- Configure
- Query
- Attributes DB Options
- Upstream Variables
- Data Preview
Step 1: Configure
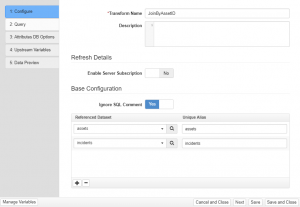
Transform Name
This is where administrator can add the name of SQL Transform.
Description
This is where administrator can enter notes for the transform.
Enable Server Subscription
- Yes – Use server subscriptions to continually fetch and cache data based on the poll rate, or poll rates of dependent upstream feeds.
- No – Data is fetched on-demand when a client subscribes and cached for the duration of a poll period.
Referenced Datasets
Choose one or more datasets that are needed for the SQL Code to access on the next wizard step. You must return to this step if you decide later to access another dataset in your SQL Code, as the editor will not allow you to access anything not chosen here.
Ignore SQL Comment
- Yes – Text inside of the comment block /* … */ or inline comment — in the query statement will be ignored
- No – The server will attempt to parse comments for edgeCore tokens nodeVar, safeNodeVar, and src which can result in server error. This option should be on in most of the cases unless you need to have /*, */ or — as part of a literal string.
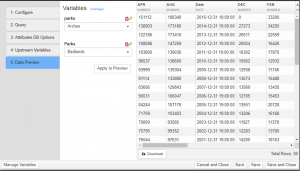
Step 2: Query
This is where SQL for the transform is entered. The input provides syntax highlighting, as well as an “Insert” button for variables, and references to other datasets in the system.
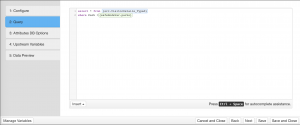
There are some pre-configured functions that ship with edgeCore, which can be useful when working with a SQL Transform:
- ToTimestamp(epochTime, isMillis): Converts epoch seconds or epoch milliseconds to a SQL timestamp type
- ToEpochTime(timestamp, isMillis): Converts a timestamp to epoch seconds or epoch milliseconds
- Delay(milliseconds): Pauses for the specific time. Primarily for testing purposes
- ToInteger(value): Converts a String type to an Integer
- ToDouble(value): Converts a String type to a Double, also known as a Number in edgeCore
Insert Options
- Dataset Alias – Allows users to insert a dataset alias entered in step 1 into the query. Example Syntax:
{src.dataset_alias} - Node Variable – Inserts a Node Variable into the query. Example Syntax:
{safeNodeVar.nodevar_name} - Secured Variable – Inserts a Secured Variable into the query. Example Syntax:
{secVar.secvar_name}
The transform utilizes the built in H2 Database, and therefore supports only the SQL Grammar supported by H2.
Quick Source Change
To quickly change the dataset being used in the SQL Code you can click on the source token to get a popup of all the available sources. Clicking the new dataset name will choose that as the new source.
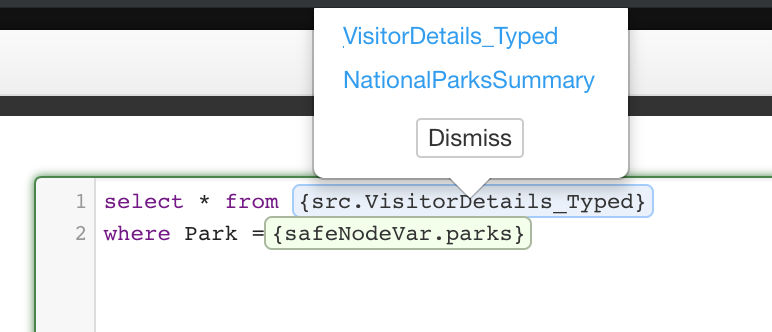
Step 3: Attributes DB Options
This is an optional performance optimization step that can be skipped. To enable Indexing on an attribute, click the checkbox next to the attribute’s name.
Refer to the Indexing section for more information.
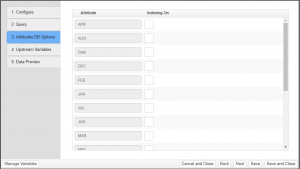
Step 4: Upstream Variables
Details about this step can found here: Satisfy Upstream Node Variables Wizard Step
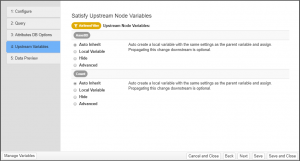
Step 5: Data Preview
Use this step to preview the resulting data. You can use the Variables sidebar to adjust the values of variables passed into the query prior to save.
Known Issue
edgeCore uses its bundled H2 database in support of the SQL Transforms. SQL that uses Common Table Expression (CTE) ‘WITH’ grammar (used to create temporary tables) is known to produce lock timeouts and also memory leaks. This has been observed to potentially create the following two issues:
- Lock Timeouts – The timeout will occur in various places, but it is caused by the locking mechanism used by H2 when the temporary tables are created and cleaned up.
- Memory Leaks – Memory goes up, as the temporary tables are not cleaned up due to the timeouts.
There is a mode edgeCore can be configured in that will eliminated the lock timeouts, but it will not eliminate the memory leaks. It can be applied by configuring the following cache db suffix in custom.properties:
db.cache.suffix=;DB_CLOSE_DELAY=-1;DATABASE_TO_UPPER=FALSE;FILE_LOCK=SOCKET;LOCK_TIMEOUT=10000;LOG=0;UNDO_LOG=0The default suffix now includes “MULTI_THREADED=1;MVCC=TRUE”, which triggers the more performant mode of H2 but leads to the timeouts when using ‘WITH’ clauses.
Migration of existing ‘WITH’ clause SQL Transforms:
- Identify the transform.
- Extract the ‘WITH’ clause into a SQL Transform; it should be off of one of the existing parents.
- You will need to add any of the sources into the upstream sources.
- Edit the Transform from Step 1, removing the ‘WITH’ clause and replacing the table name it was generated with the new transform source created in step 2.