edgeCore version: 4.3.7
A robots.txt file contains instructions for search engine web crawlers that tell them which web pages they can and cannot access.
Creating a robots.txt file
- Use any text editor to create a robots.txt file (for example, Notepad or TextEdit).
- The name of the file needs to be robots.txt.
- Add rules to the robots.txt file.
Rules are instructions for crawlers so that they know which parts of your website they can crawl. The robots file consists of one or more groups that include the following directives:
– User-agent: The directive is required and is the first line for any group. It specifies the name of the search engine crawler that the rule applies to. If you use * for user-agent, then the instructions apply to every crawler. If you want the instructions to apply to a specific crawler, you will need to name it (for example, User-agent: Googlebot-News).
– Disallow: A directory or page that you do not want the user agent to crawl.
a) If you want to block crawlers from crawling a page, the full page name as shown in the browser after the homepage (for example, edgeti.com) must be included (for example: /edgecore-product-updates/)
b) If you want to block a directory, the name of the directory must start and end with /
c) If you want to hide the entire website, just enter / after Disallow:
d) If you want to allow crawlers full access to the website, you do not need to add anything after Disallow:
– Allow: A directory or page that can be crawled by the user agent. This will override a disallow directive to permit crawling of a subdirectory or page in a disallowed directory.
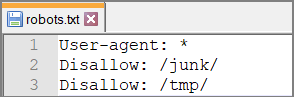
Robots.txt file example
Uploading the robots.txt file to edgeCore
You can have only one robots.txt file. This file should be added to edgeCore’s static-web folder.
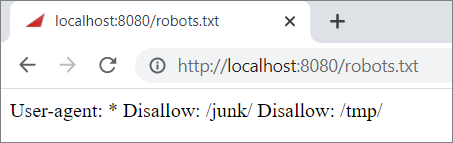
Testing the robots.txt file
- In your browser, go to http://localhost:8080/robots.txt
- The content of the robots file you have created and added to the static-web folder will be displayed.