For Each transform takes 2 sources — Master Dataset and Detail Dataset. This transform iterates over each record in one source dataset (Master Dataset), and for a given column of data on the Master Dataset, each unique value is inserted into a node variable on the Detail Dataset to produce a new dataset.
Furthermore, For Each transform enables you to:
- Define the data you need, instead of having to pull in the entire database;
- Define the number of simultaneous requests that are allowed (default is 4);
- Reduce load on the database;
- Refresh/update data automatically;
Note: Only changes in the Master Dataset will trigger the For Each transform to run.
Example
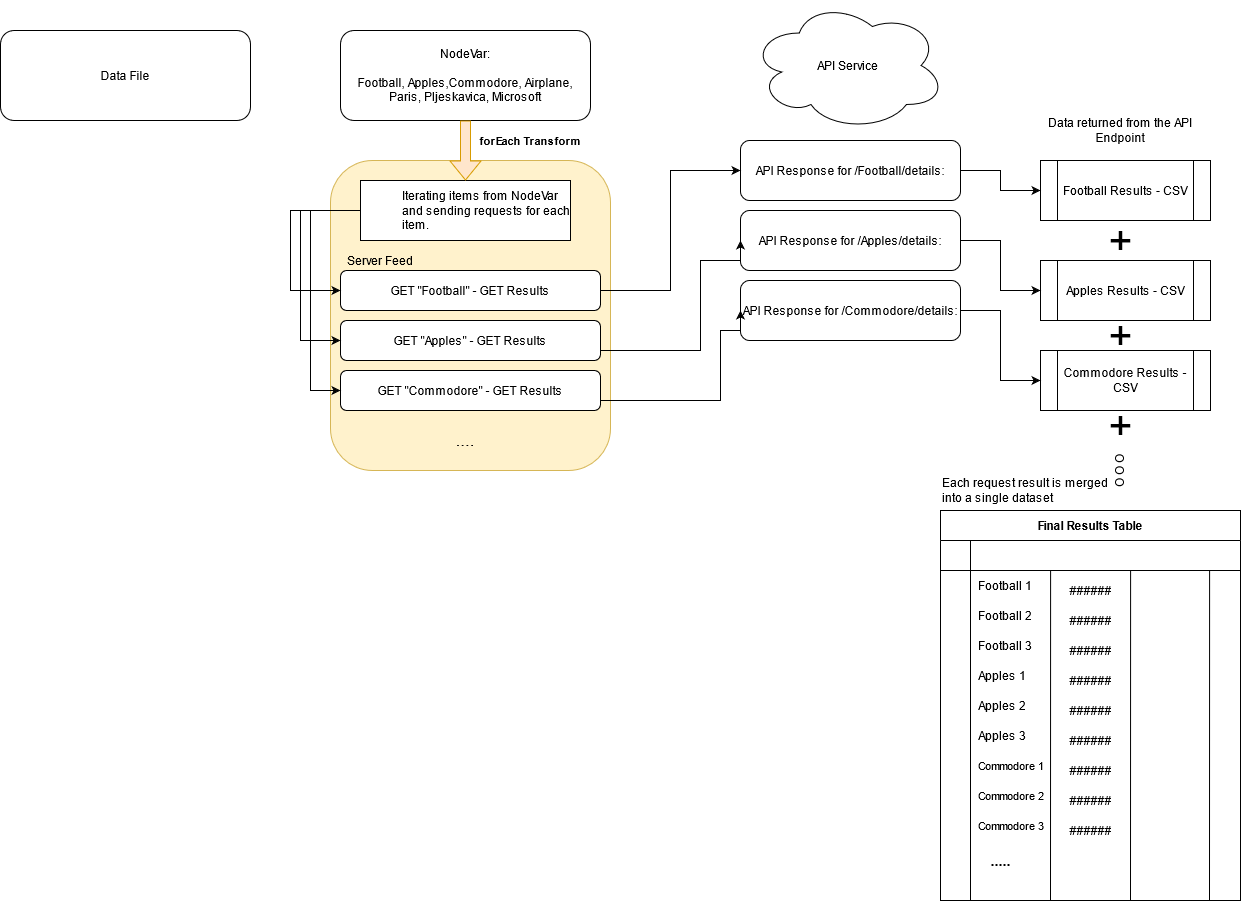
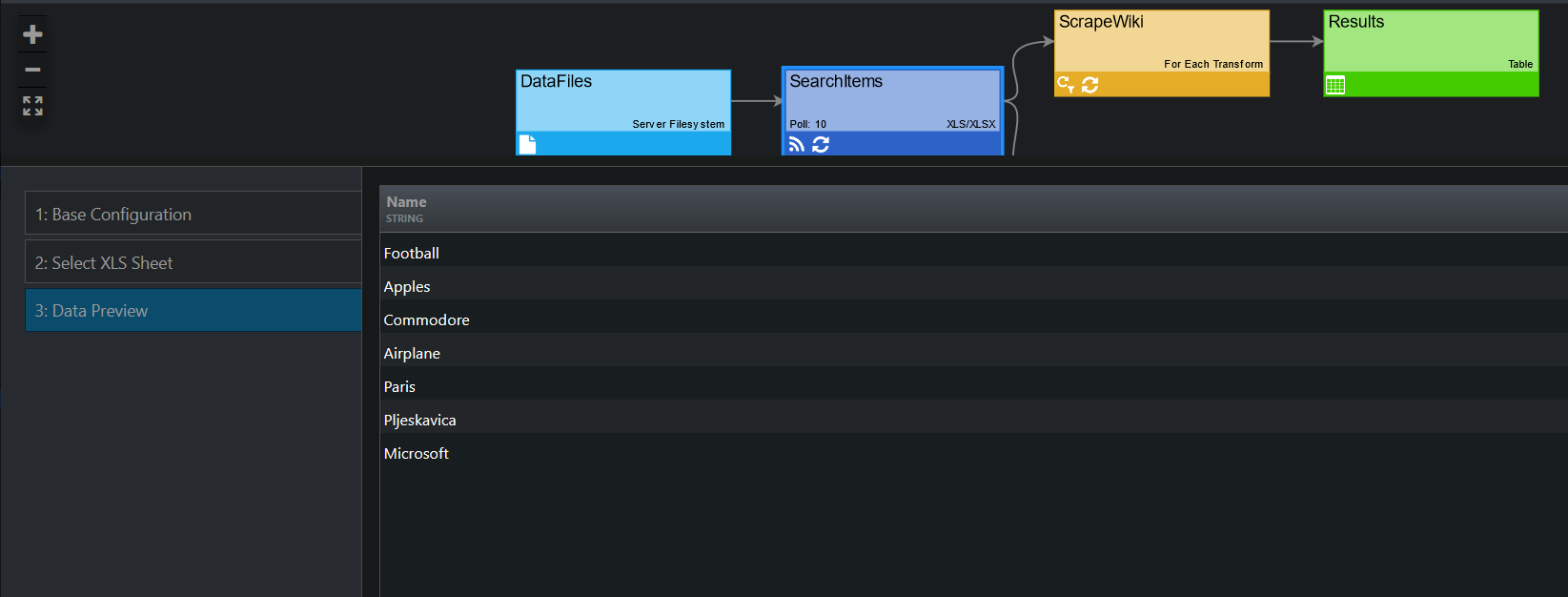
In [INSTALL HOME]/data, we have a searchitems.xlsx file (master dataset), which contains the Name column and the following items: Football, Apples, Commodore, Airplane, Paris, Pljeskavica, Microsoft.
We proceed by creating a Server Filesystem connection type and then the XLS/XLSX feed type, containing the above-mentioned search items that will be used to scrape Wikipedia.
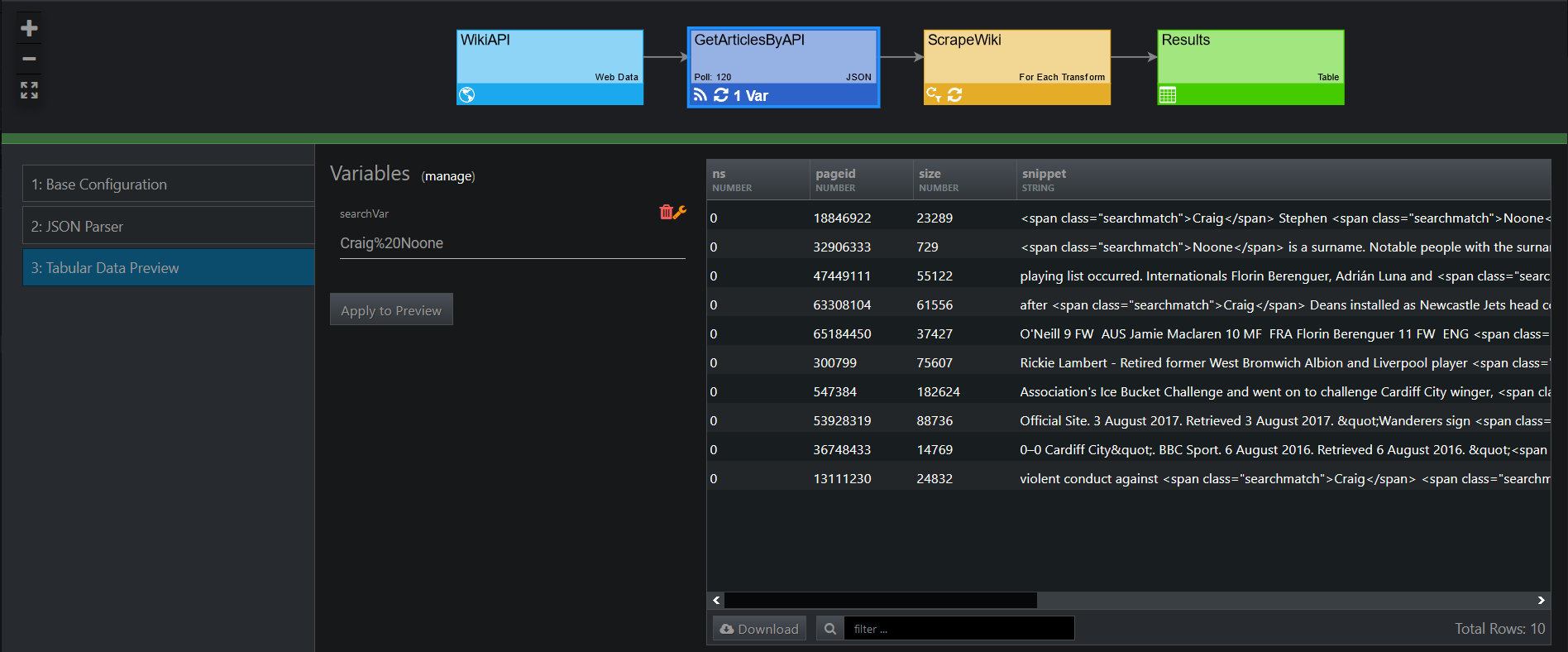
Afterward, we create a web data JSON feed (detail dataset) that will scrape the Wikipedia API for the above-mentioned items.
Having done that, we can create a For Each transform (refer to Configuration below). As a result, once all search items are iterated through, and edgeCore receives datasets from each API response, all results will be merged into a single dataset.
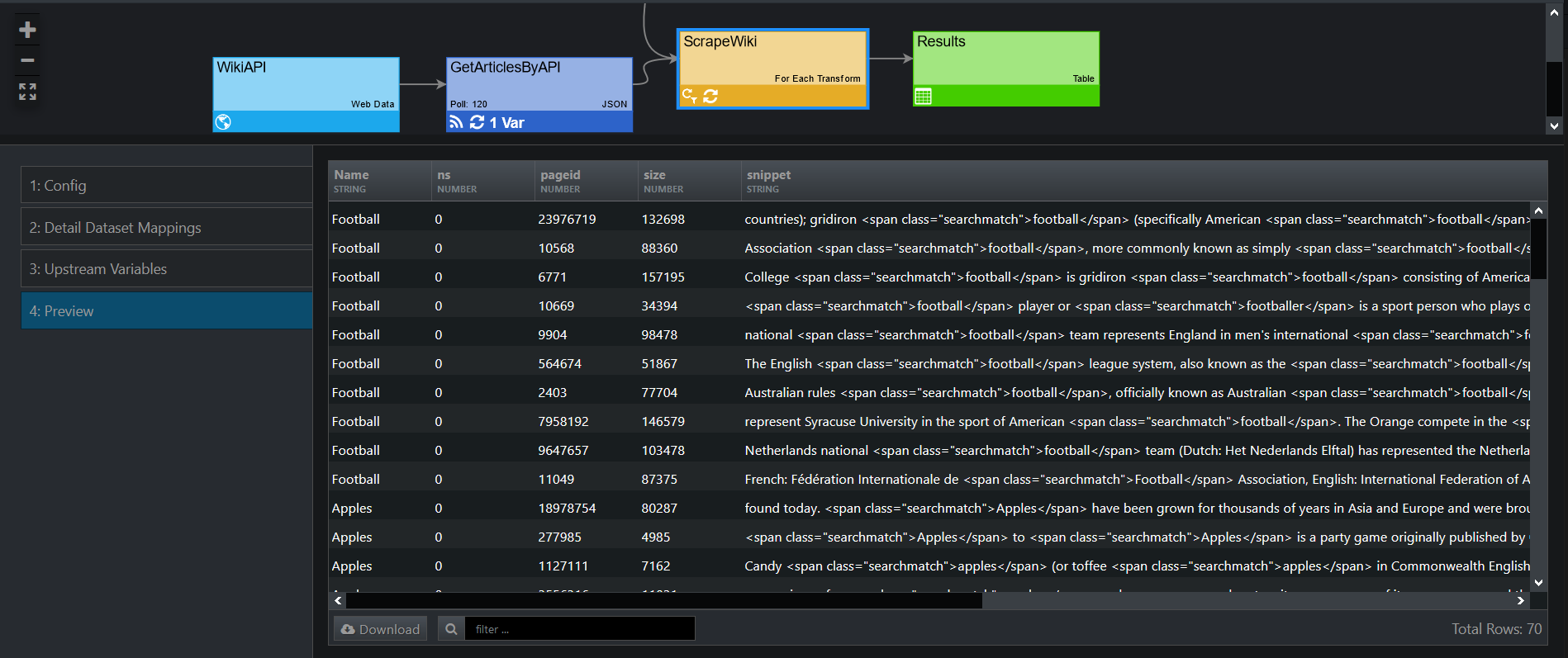
This is what our pipeline looks like:
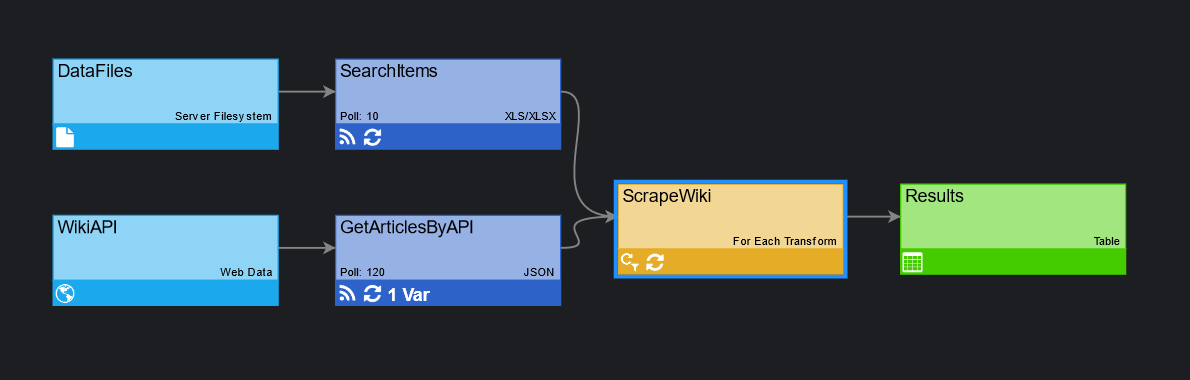
Configuring For Each Transform
To create a For Each transform, take the following steps:
- Select For Each Transform as the transform type.
A new page is displayed. - On the Config tab, do the following:
a) In Transform Name, enter a name for the transform.
b) Turn on the Enable Server Subscription toggle switch in order for data for this transform to be continually fetched, updated, and cached.
c) From the Detail Dataset dropdown, select the dataset.
As previously mentioned, for a given column of data on the Master Dataset, each unique value will be inserted into a node variable on the Detail Dataset to produce a new dataset.
d) In Max Concurrent, specify the number of simultaneous requests that are allowed.
Default is 4.
e) Click Next to go to the next tab. - On the Detail Dataset Mappings tab, do the following:
a) From the Attribute dropdown, select the master attribute to iterate.
In the example above, our master attribute was Name, as seen in the SearchItems XLS feed.
b) From the Variable dropdown, select the detail dataset variable.
In the example above, our detail dataset variable was searchVar, as seen in the JSON feed.
c) Click Next to go to the next tab. - On the Upstream Variables tab, specify how to satisfy the node variable(s).
– Auto Inherit: If this option is selected, a local variable with the same settings as the parent variable will be automatically created and assigned. There is no need to propagate this change downstream.
– Local Variable: If this option is selected, you will be prompted to select a local variable to satisfy the upstream variable. Also, downstream nodes will have to satisfy this local variable.
– Hide: If this option is selected, the value of the parent node variable will be set to its default value. Also, the variable will be hidden downstream, as there is no need to satisfy it.
– Advanced: If this option is selected, you will be prompted to manually enter the advanced mapping value. - Click Next.
You are taken to the Preview tab, where you can view the aggregation of the returned detail data. - Click Save and Close.
The transform is displayed in the pipeline.
edgeCore 4.4.2 version
ForEach transforms are shown in a different color in the pipeline.
