A filter node limits what is in a dataset. This operation can:
- Filter records, affecting the number of rows returned.
- Filter attributes, affecting the number of columns returned.
It also contains additional logic for how the resulting dataset is sorted.
Step 1: Config
This step defines the base configuration for the filter.
| Properties | Description |
|---|---|
| Transform Name | This is a symbolic name that will be used to identify the resulting dataset and represent this node in the pipeline. |
| Description | This is where the administrator can enter notes for the transform. |
| Enable Server Subscription | Yes – Use server subscriptions to continually fetch and cache data based on the poll rate, or poll rates of dependent upstream feeds. No – Data is fetched on-demand when a client subscribes and cached for the duration of a poll period. |
Step 2: Attributes
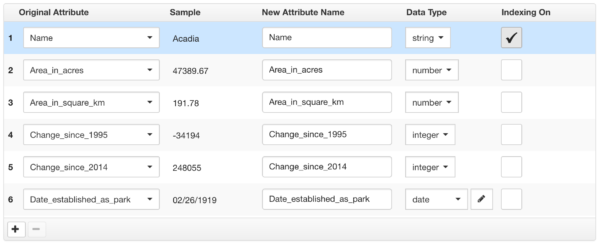
This step contains logic to filter Attributes from a dataset. It affects the number of columns returned and is equivalent to a SELECT statement in SQL. The user interface for this step is a list builder that builds a list of the attributes to return.
In edgeCore 3.0, this step will be pre-populated with all attributes in the dataset and a default type will be provided for all attributes that can be determined.
- An administrator can remove any unwanted attributes by clicking the “remove” icon
 in the footer. This removes attributes from the resulting dataset, filtering out unwanted columns.
in the footer. This removes attributes from the resulting dataset, filtering out unwanted columns. - An administrator can add additional attributes by clicking the “add” icon
 in the footer. Duplicate attributes are often used with different renderers. One column will have an icon renderer, and another will have a text label.
in the footer. Duplicate attributes are often used with different renderers. One column will have an icon renderer, and another will have a text label.
Step 3: Filter
This step contains logic to filter records for a dataset. It affects the number of rows returned, and is equivalent to a WHERE clause in SQL. The user interface for this step contains an expression builder, which contains rules for evaluating values for specific attribute names. This accommodates both simple property comparison, as well as more advanced expressions. Refer to the sections below for more detailed examples.
Note: Data Type change is done upstream. For example, on the Attributes tab, you have an attribute whose data type is a string, and you change it to a number. However, on the Filters tab, this attribute’s data type will still be displayed as a string (that is, as it was upstream).
Static Property Comparison
A Static Property Comparison filters records based on values for a single attribute. For example, assume a dataset with event data, and assume end users are only interested in the critical events. The records need to be filtered by the values for a specific attribute name.
- Assume the attribute name containing severity values is “Severity_Name”.
- Assume the records of interest have a STRING value equal to “Critical”.
The resulting filter is shown below:

Rule Pattern
Notice that each rule has the same general pattern.
| Attribute Field | Choose the field in your data that you would like to write a rule against. |
|---|---|
| Operator | This determines how to evaluate the specific value. – Numeric Rule Sets allow numeric operators like <, >, and =. – String Rules Sets allow string operators like EQUALS and CONTAINS. |
| Value | This represents a value you expect to find in your data. |
Static Expression
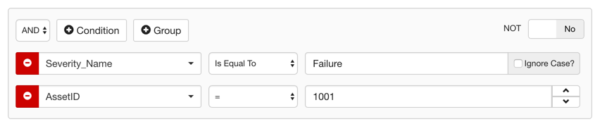
This type of filter checks values from multiple attributes using AND/OR operators. For example, assume a dataset with event data, and assume end-users are interested in critical events for a specific AssetID. In this case, the records need to be filtered based on values contained in two different Attribute Names:
- Assume the attribute name containing severity values is “Severity_Name”.
- Assume the attribute name containing asset IDs is “AssetID”.
- Assume the records of interest have a Severity of “Critical”, and an AssetID of “1001”.
The resulting filter is shown below:
Step 4: Row Limit and Sort
Row Limit
This step provides a way to cap the number of rows returned.
- It can be used for performance reasons, to prevent too many records from being returned.
- It can be used for “Top 10” types of summary views, where only a fixed number of records is desired.

Note: Row Limit = NO will return all rows.
Sort
This step defines how the resulting records should be sorted. The Sort user interface is a list of builder control that supports multi-column sorting. The first item in the list represents the primary sort. Each additional attribute produces a sub-sort, based on its parents.
The example below will sort the resulting dataset by severity first. Records that have the same value for Severity_Name will then be sorted by “AssetID”.

Step 5: Upstream Variables
Details about this step can found here: Satisfy Upstream Node Variables Wizard Step.
Step 6: Preview
This step provides a preview of the resulting dataset. It exposes upstream variables to test how inherited context changes will affect this result set.