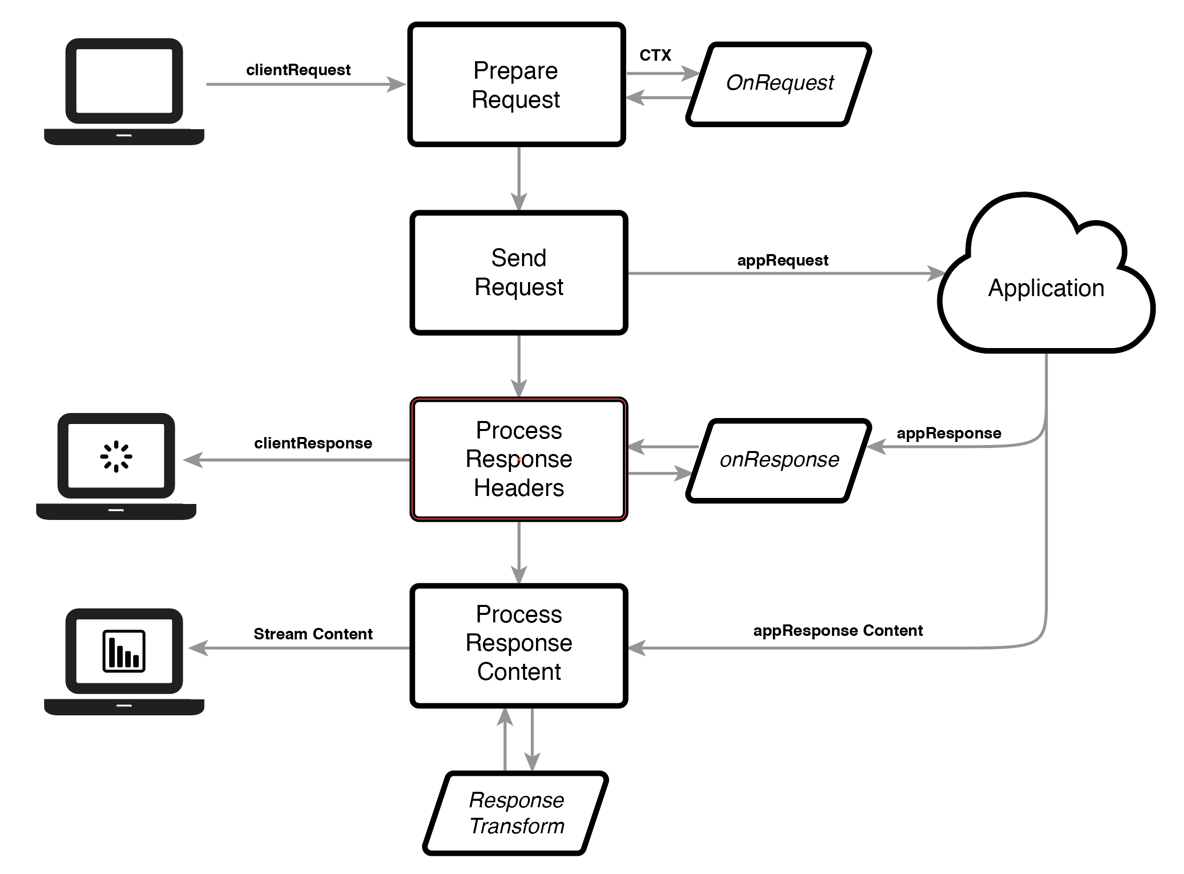
Content rules apply to both web content and web data feeds. These rules are involved at three different points in the processing of a client request:
-
- On receiving the client request, we prepare an application request to be sent to the application server. The basic request is created by the framework and then passed to the content rule’s
onRequestmethod to perform any required manipulations. Once these are done, the request is sent. - On receiving the application’s response headers, the framework creates a basic response for the client based on this. The content rule’s
onResponsemethod is then called to:
a) perform any required manipulations to the client response
b) perform any actions based on the application response
c) set up any response content transformations - Though the content rules are not explicitly invoked in this case (as the framework streams the response content from the application to the client), any transformations set up during the response header handling are applied.
- On receiving the client request, we prepare an application request to be sent to the application server. The basic request is created by the framework and then passed to the content rule’s
Base Rules
The BaseWeb and BaseData rules provide generic functionality to facilitate proxied access to backend applications for web content and web data respectively. Most other rules delegate to one of the base rules, and often this will be enough to provide almost all the functionality required to successfully access application content via edgeWeb.
BaseWeb
The BaseWeb rule covers these main areas of functionality:
- Redirection: the
BaseWebonResponsemethod examines the application response’s status code and ensures that theLocationheader forwarded to the client is properly mapped so that the subsequent request is made via edgeWeb. - URL mapping: because edgeWeb essentially acts as a reverse proxy, documents returned by the application server must be scanned for URLs referring back to the application server. These URLs may need to be modified before being forwarded so that they refer to the application through edgeWeb instead.
BaseData
The BaseData rule is a thin layer on top of the BaseWeb rule. The BaseData rule sets the response transformation pipeline’s mode to be BINARY, which means content is passed through without interpreting it or applying any transformations. Any transformation is deferred to the edgeData pipeline, where the various parsers – JSON, XML, CSV, JavaScript perform the initial normalization, after which the standard transforms and visualizations can be applied.
Content Transformation
The main focus of content transformation in the base rules is URL mapping, and manipulation of content. Web adapters delegate to the base rules for URL mapping, and this is often enough. If there is a requirement to integrate application content into reports or dashboards, then more application specific adjustments may need to be made to content being forwarded to the client.
Content Isolation
It is often useful to be able to isolate specific functionality of an application and have it appear a natural part of any Page it is placed on. The preferred method of isolating content is to identify a URL that returns a document that represents only the desired content and use that as the Start URI for the relevant Web Content feed. In this case, content transformations can help remove any framing decorations –headers and menus for example to isolate the useful content. Broadly speaking, there are three main approaches to removing content from a document:
- Hide it – either by modifying the relevant CSS document, or changing an inline style attribute;
- Remove it – for static content, a pattern or range match can be performed, and the content can simply be omitted from the forwarded response. If performed successfully, there are obviously no possible presentation glitches involved in this case, as the content never arrives at the client;
- Prevent it from being retrieved – sometimes it is possible to modify the JavaScript that causes parts of the displayed content to be retrieved;
URL Mapping
URL mapping is relatively straightforward where static content is involved – pattern matching and replacement performed by the base rule is usually enough to deal with it. Issues arise when URLs are constructed, which is becoming more common in modern web applications.
For applets, changing the requested URLs is essentially not possible. However, if the applet is well-written, then it will primarily use relative URLs. Relative URLs will work, as they are relative to the (already mapped) URL of the document in which the applet is embedded, so they don’t require mapping.
Additionally, the Tomcat container in which edgeWeb runs is quite strict about which characters it allows in requested URLs. Sometimes this presents a problem when the application being proxied is more relaxed: the container rejects the request before edgeWeb gets the chance to service it. This can be non-trivial to deal with, as the characters in question are usually contained in the query string, and this is often generated dynamically in JavaScript code. For reference, Tomcat rejects requests with any of the following unescaped characters in the request line:
| Character | Description |
| ‘ ‘ | Space |
| ‘\”‘ | Double quote |
| ‘#’ | Pound/Hash |
| ‘<‘ | Left angle bracket |
| ‘>’ | Right angle bracket |
| ‘\\’ | Backslash |
| ‘^’ | Caret |
| ‘`’ | Backtick |
| ‘{‘ | Left curly brace |
| ‘|’ | Pipe |
| ‘}’ | Right curly brace |